We are looking for developers (any language) to join us in a short feedback session, to get input and comments on a unique business model that is in the proof of concept phase. Would you have 30 minutes for a feedback session?
This is an update of the existing developer docker environment, geared towards developers of:
ApiOpenStudio Core
ApiOpenStudio Admin
Plugins
Connectors
It is not ready for full public release yet, because it implements the new ApiOpenStudio Docker Dev, which is still in pre-release.
However, it has some brilliant new features:
Uses Traefik as the reverse proxy (faster and better than Nginx reverse proxy).
All logging in a single place from Traefik and ApiOpenStudio (easier development processes).
A Makefile to simplify setup, initialisation and day to day usage (easier and faster setup and usage).
Example settings file, allowing you to get up and running in under 20 minutes (no need to worry about debugging your initial setup).
Persistent DB, stored in a docker volume for security, space-saving and portability.
Full HTTPS support and setup
Tested and working on all major OS’s:
Mac
Linux
Windows
The only requirements on the host OS:
Docker
Git
mkcert
Fully documented in the README, including FAQ for possible common issues and howto’s.
It will be a new major version release, will not be backwards compatible with the existing v1.x.x of apiopenstudio_docker_dev. Because of this, it will remain in the develop branch until apiopenstudio_admin_vue is ready for alpha release at the earliest.
This will enable a sneak preview on progress in the new Admin interface, that will include a drag n drop interface (for even faster and simpler development), and fully revised UX/UI.
We are about halfway there now, with the following completed:
Routing
Templates for different page layouts
Resource development page
Drag ‘n’ Drop interface
Lists of processors (nodes) in the system
JSON view
YAML view
Ability to switch between the views with data loss
Import/Export resources locally
Processor info slideout drawer
Ability to enter input constants
Centre and zoom the view on the existing design
Re-order the nodes in the GUI
Applications page
Notifications modal
Home page
Unit testing (Vite)
E2E and Component testing (Cypress)
Styleguide (yarn styleguide)
Jdoc (yarn jdoc)
Theming
Light/Dark mode
The develop branch on ApiOpenStudio core has been updated to include a refresh token. This extends the JWT functionality, so that when the existing login token expires, the user does not need to log in again (unless they have been away for over 1 week).
The next phases includes:
Adding unit tests for the conversion between Drag ‘n’ Drop data to JSON/YAML
Login & token refresh functionality
Replacing stub data with real API calls from an ApiOpenStudio core instance
This document solidifies and defines the multiple definitions and sub-genres within the Low-Code and No-Code world.
No-Code – A visual software development environment where the user works only within a GUI. There is no programming or CLI involved. The system potentially allows plugins for added functionality.
Low-Code – A visual software development environment using a GUI and/or SDK. In addition to No-Code functionality, the user has the capability to also add programmatic code directly in the environment. The system potentially allows CLI and plugins for added functionality.
Low Code No Code (LCNC) – Low-Code and No-Code as a technology, referring to all or parts of a system.
Pro-Code – Single or multiple systems that are written in pure code, by a programmer in whatever language suits the task best.
Background
Low-Code and No-Code have been around for several years, and the genre was first proposed in the 1982, when James Martin argued in his “Applications Development Without Programmers” book that 4GL technologies (such as RAMIS and FOCUS) “opened up the development environment to a wider population and enable non-programmers to create applications themselves” (Sassi, R.B. (2021). A Brief History Of Low-Code Development. [online] Medium. Available at: https://betterprogramming.pub/low-code-history-b756c095494f). As a response to the Waterfall Model, RAD gained momentum in the 1990s when the concept of visual desktop tools like Visual Basic, Delphi, and Oracle Forms became popular. Low-Code and No-Code gained wider traction in 2016, after a publication by the Forrester Group that made the term Low-Code public.
Since then, Low-Code and No-Code applications have enabled skilled developers to work faster and citizen developers to work on tasks that do not require as much technical knowledge but were previously purely within the remit of developers.
However, the fluidity and misuse of terms and labels describing this technology has caused a lot of confusion. In specific:
Formal definitions of the differences between Low-Code and No-Code are sparse and no two people describe them in the same way.
Two other terms have appeared recently: LCNC and “Low Code No Code”, both of which appear to define different things.
LCNC has often been used by the Low-Code community to describe how all the platforms have evolved by adding UI for repetitive tasks, i.e. small areas of No-Code to their platforms. Many Low-Code platforms offer No-Code functionality as well, such as Appian, Mendix, Microsoft PowerApps, OutSystems and Salesforce Lightning.
“Low Code No Code” has been used in the media to refer to all Low-Code and No-Code coding types as a whole (i.e. not Pro-Code). This phrase is mentioned as much, if not more than LCNC.
Solidifying the terms
In theory, the differences between LCNC and “Low Code No Code” are redundant and using an acronym of one term to mean something different to the expanded term leads to a lot of confusion. Therefore, we should have a single definition for LCNC and “Low Code No Code”, and only utilise LCNC as an abbreviation of “Low Code No Code”. Therefore “Low Code No Code” and LCNC should hereon refer to all Low-Code and No-Code coding types. This can apply to the entire application or part of it.
Despite the limited definition in the public domain for No-Code and Low-Code, we can lean on the two words “Low” and “No” to express pure UI drag ‘n’ drop interfaces vs GUI that also allow code (i.e. nearly No-Code).
So No-Code refers to applications that exist 100% in the GUI (drag ‘n’ drop and configuration).
Low-Code also exists in the GUI, but it also allows the user to define code, either in the GUI, SDK or CLI. Low-Code is different from No-Code in that it is much more flexible, however you need developer skills to use it (though less than traditional Pro-Code, which is the ultimate for flexibility). Low-Code has an advantage over No-Code, in that it is much more flexible than No-Code and can be used by a Junior Developer to move much faster than a Pro-Code approach.
Formal definition
No-Code
A visual software development environment where the user works only within a GUI. There is no programming or CLI involved. The system potentially allows plugins for added functionality.
Low-Code
A visual software development environment using a GUI and/or SDK. In addition to No-Code functionality, the user has the capability to also add programmatic code directly in the environment. The system potentially allows CLI and plugins for added functionality.
Low Code No Code (LCNC)
Low-Code and No-Code as a technology, referring to all or parts of a system.
Pro-Code
A system that is written in pure code, by a programmer in whatever language suits the task best.
We have released a new video on YouTube, demonstrating the speed and ease of deployment: spinning-up full running API and Admin installations on separate servers in under 30 minutes!
This is a response to the discovery of an issue with the admin Docker image at the end of last week. The issue was resolved over the weekend and the docker images have been re-published.
While preparing for yesterday’s seminar, it was found that the naala89/apiopenstudio_admin docker images were broken (the issue can be viewed here).
The good old fashioned “it works on my machine” came back to bite us, but the code has been updated and it is now loomed correctly into the GitLab pipelines. Many thanks to laughing_man77 for jumping on this so quickly!
Problem solved!
We’re pleased to announce that the issue has been resolved, and all tags have been re-uploaded to docker hub. So that was a really quick turn-around of 1 day (and we even had a chance to sleep on it before pushing it live).
Apart from the good news that full production images for ApiOpenStudio core and admin are fully working and tested, I also tested the released image on an existing server – and proved that the install time of admin is under 5 minutes!
The latest off the hot-press: We have finalised and published the docker creation pipelines. This now means that you will continually have the latest version of ApiOpenStudio Core and Admin images at your fingertips.
The images are very fast and easy to install and completely self-contained (server and all requirements, including Composer dependencies). That means that you do not need to install any infrastructure on a barebones server, except for Docker, config file and SSL certificates. See:
The scripts are configured to generate images from tags or any branches we want to release (this includes develop/master branches and any development branches that we deem necessary for testing).
Full documentation of the installation process is available on our wiki at:
The scripts are available at the GitLab docker repository (Core and Admin), and I’ve also taken a little time out to post a gist of one of the scripts that others may find useful (download a specified branch or tag from a GitLab or GitHub into a location) at https://gist.github.com/naala89.
The topics include: an introduction to the product and a run through of all the basics of the technology, and where you save time and money.
Followed by Q&A on the Product and the Business Concept.
No need to register as we will be live on YouTube. However if you would like to register, we are offering a free 90 minute support package to anyone who registers.
To register, fill in the contact us form on the home page.
APIs are displaying continued astronomical growth (see https://www.postman.com/state-of-api/api-global-growth/#api-global-growth) and are now a critical part of nearly all modern architecture. However, we have seen a lot of coverage recently of the different terms encompassed by the API First methodology, especially as people try to use these buzz-words to generate excitement over their products without fully understanding what they mean.
In IT, terms tend to evolve, due to the pace of change. But this is not the ideal way to create terms as it can lead to similar terms, causing sub-optimal communication, even mistakes. But unlike industries like aviation and maritime, which are the gold standard for communication, w do not set a standard and declaration for what precise terms to use and when, to prevent confusion, misunderstanding and planes and boats crashing into each other.
For instance, we now have the following:
(Yes, I know that some of these are unrelated to APIs, however there is a real problem with language here – everything sounds the same and confuses people)
I don’t know about you, but my head is rattling from all of these variants. This is getting ridiculous and incredibly confusing for everyone, requiring a lot of reading of articles to understand the nuances of the new terms that are being introducing and how these may subtly differ from the others.
As technologists, we need the business community to fully grasp the ideas and benefits behind the API first methodology so that we and they can make sound judgements on directions and strategies. This means that the ideas need to be immediately comprehensible and their ramifications obvious.
I am going to suggest that we throw out a lot of these phrases and keep things simple, but I won’t try to reinvent the wheel and create completely new phrases. For the rest of this article, I will only refer to 3 terms.
API First concepts
Each term has an impact on the technical and business strategies/successes in different measures. But each concept requires a full “buy-in” and understanding from the business.
API First
Design the and build the API first!
The product is built around the API.
This is reflected in the business strategies and revenue models (see API as a product and API design 1st).
API-first is obvious from the business point of view. The API is the primary income generator or essential to other income product/s. Without a revenue model, you do not have a business. Therefore if APIs are the main product or critical to a product that is being created/overhauled, then the API becomes a crucial first-class citizen, not just for the technical dept, but also from the business.
Information and data are key to the modern business, right? APIs are the backbone for nearly all data communication.
Building a new product (not just API) is an expensive task, both in time and money. By going through a full design phase for the API, the correct emphasis and attention is given to the API that it needs, a lot of thought will be put into:
What data is being shared across the API.
Why this data sharing is required or wanted.
Who/what will be consuming the data (internal and/or external).
This will reveal any potential flaws or opportunities in assumptions that the business has made.
Ensuring that all business processes are made more efficient by the new agile data flow that APIs will provide.
Performance.
Reliability.
Scalability
Usability.
pricing.
Future changes/versioning.
n return, API First will have a causal effect on the business by ensuring that due diligence and research is followed before embarking on a costly venture of system build. A lot of thought will be put into what the business needs and why. Future projections and plans become much clearer.
This does not mean that all other resources sit in idle-mode until the API is built, in fact it can happen simultaneously. Once you have the API model built in documentation like OpenAPI or Redoc (quite early in the process), you have a model that can be used by consumers before you start the full development. This saves time and money on fixing broken assumptions, missing or inadequate requirements.
API as a Product
The API may be the core product, but not necessarily.
API as a product has 2 definitions:
External-facing API that is monetised
Indirect monetisation by a product that requires an API to function or public exposure and usage through a free public API.
API as a product, is tightly coupled to the API design-first concept. In order to implement business strategies for revenue driving APIs, good design and documentation is a “must-have” to enable third parties to consume the APIs, providing an easy-to-use, comprehensive and unified experience.
If the API product is well designed and documented, this will increase the consumption and efficiency of the API (and therefore income). Postman alone has seen very significant increases in traffic and API usage, despite the global downturn and Covid:
Since the 2021 State of the API report was released, the Postman API Platform saw significant surges in use: * Users: 20 million * Collections created: 38 million * Requests created: 1.13 billion
In general, this is a development model for APIs that ensures the following criteria are met:
Reach agreement from all stakeholders.
Design the APIs models first on OpenAPI or similar product.
Build the API.
Separate products can be built at the same time as the API.
API design first may not be quite so obvious from the business POV, because at first view, it is just a development process. However, because it requires approval from all stakeholders, it is critical to have business “buy-in” to the process. This enables all of the business to see what/why the API is being built, and ensures that everyone is agreed on the most critical features they need.
In addition, this results in a rare instance of a complete understanding of what is being built and why, by the technical department. Instead of just being told to “build this” by the business without any consultation between them on what the rationale is, what is technically feasible, or if there is a better solution, the developers and department see the vision and are able to work towards that vision in a much more efficient manner and the end result will be a much better product.
Conclusion
This all ties in with discoveries and revelations being made about “Developer Experience”.
Up until recently, a lot of research and time has been invested un user experience (UX) and there is no denying the value that this can contribute to the business by increasing traffic and revenue. However a new key realisation is being made about developer experience (DevX). Who will be directly interacting with and consuming the APIs (and therefore making critical decisions that will impact their business about what APIs to consume and the frequency)? That right, developers!
They will correctly discard badly documented or difficult to use APIs in favour of better APIs. This means your product will be directly impacted by the DevX experience!
If you are supplying an external facing API for revenue (direct with monetisation or indirectly by offering APIs free with the associated traffic, publicity and exposure), then DevX is crucial to maximise income.
If you are supplying an internal facing API, then good DevX will have an impact on associated systems design, development and maintenance. Business processes that interact with the API will be either made more efficient by a well designed API or made cumbersome slow and inefficient by bad APIs.
We are excited to announce the official release of the Beta Version of ApiOpenStudio!
We have worked very hard on this release, and the release includes a lot of bug-fixes, enhancements and requested features. Here is a quick overview up the updates:
We now are seeing an exciting, 27% month on month growth in our install base of the Alpha version (ok “exciting” that’s a marketing term. We don’t normally use them, as that’s not us, but humour me – I think that’s what we are supposed to say).
We are particularly happy about this as we took the decision to launch ApiOpenStudio in an advanced form of Alpha. So we could get early feedback and build the best open source product possible.
So to celebrate this, and the approaching Beta release, which we now estimate is now only 3 months away.
We are offering a free 30 min support package to anyone who has downloaded the product.
As this will support our early adopters, as well as give us the best possible feedback. The key to building the best product possible.
This will be with our founder John (wherever possible), as we really want to get the maximum from this customer interaction.
So if you would like to take this up, please reach out to Matthew Greally on LinkedIn or the Contact Us form.
After finishing and closing a large chunk of tickets for the tickets that we have planned for the beta release, we had a minor panic…
Api Open Studio Admin has largely been neglected (because it was just supposed to be a quick fix MVP and will be completely replaced before v1.0.0) while we focused on the backbone part of this project: the API (Api Open Studio). However, it was no longer compiling, due to package.json issues and it needed updating to utilise and match changes in the API core resources that it consumed.
This has been quickly resolved and new release tags added so that are now on packagist:
The findings in this report are golden and kudos to the PostMan team for producing a well-balanced and researched report (https://www.postman.com/state-of-api/, 2021).
Its findings are highly encouraging, and reading between the lines, are a fantastic indicator that the industry is on target for a continued adoption of mobile-first, API-first and micro-service architecture.
Our key take aways from this report:
The API ecosystem is global and growing
Postman reports continuing growth in API activity:
Users: 17 million
Collections created: 30 million (up 39%)
Requests created: 855 million (up 56%)
There are many more people, other than developers using APIs
Breakdown of roles consuming APIs
Developers are spending more time with APIs
< 10 hours/week: 33%
10 – 20 hours/week: 39%
> 20 hours/week: 28%
This was a rather surprising set of stats, and probably due to the respondents coming from API driven developers.
API first methodology
Encouragingly, there is increased awareness of the API-first methodology, and more businesses are approaching their architecture in this way:
Companies embracing API-first methodology
Sadly, there was an inconsistent or lack of understanding of what API-first actually meant:
Defining API-first
Public vs Private vs Partner
Of interest here is that the vast majority of APIs are intended for private use within companies. This ties-in with the API-first methodology, where APIs are considered first-class citizens in the (Understanding the API-First Approach to Building Products, 2021)
APIs are treated as “first-class citizens.” That everything about a project revolves around the idea that the end product will be consumed by mobile devices, and that APIs will be consumed by client applications. An API-first approach involves developing APIs that are consistent and reusable, which can be accomplished by using an API description language to establish a contract for how the API is supposed to behave.
Public vs Private vs Partner
Private (only used by your team or your company): 58%
Partner (shared only with integration partners): 27%
Public (openly available on the web): 15%
Lack of time was the biggest obstacle to producing APIs
Over 45% of API developers claimed that their main impediment was lack of time.
JSON Schema is by far the biggest specification tool for APIs
JSON Schema was by far the top specification in use, cited by three-quarters of respondents
Now this one really surprised us (we had assumed it would be OpenAPI 3.0, but that was below Swagger 2.0. Considering that the API documentation standards have still not coalesced into an accepted standard, there should be no surprises in movements here, and it has to be said that JSON Schema is fantastic, especially for defining complex, nested object types.
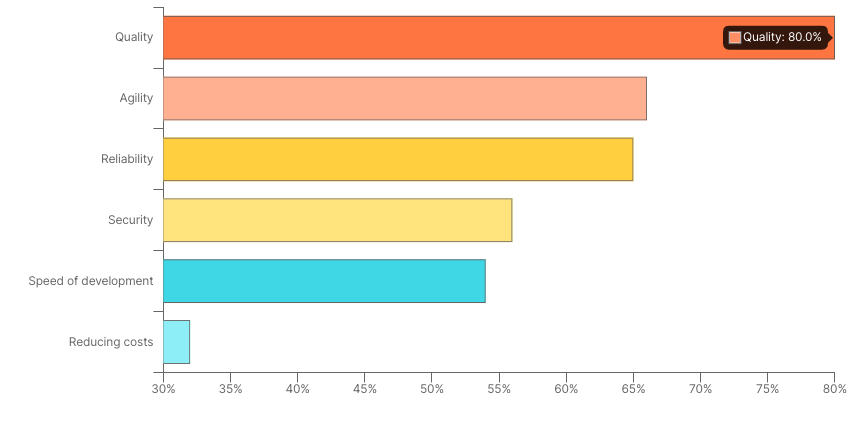
Quality is the biggest priority for APIs, above security
Respondents identify the top priorities for their development teams and organisations
This was also a surprise to us, although it transpires that a lot of APIs consume public APIs and therefore we assume that when quality is specified, they mean quality of data and resource specification. Therefore leading to a better resource offering and more consumers of it.
In order to implement pipelines and docker, with automated builds of docker images, the ApiOpenStudio projects have all been added to a new ApiOpenStudio group in GitLab.
This will enable GitLab pipelines to orchestrate pipelines across all of the projects as code is pushed and merged.
There was a dependency on this for upcoming tickets and tasks, so the tasks could not be delayed any longer. Because of this change, we have merged the develop branch to master branch, because this will update the wiki and phpdoc to reflect these changes.
However a new release tag for packagist has not been generated at this stage, becase we are only a few tasks away from beta release.
Wiki pages updated (#118 – closed & #115 – closed).
Fixed CI artefacts not being uploaded on failure (#117 – closed).
Logging now works on PHP8.0 as well as PHP7.4 (#111 – closed).
This involved deprecating Cascade, and creating a wrapper for the awesome Monolog package.
Implemented full JWT token authentication (#101 – closed).
Fix automated unit and functional tests (#110 – closed).
The entire project code has been updated to ensure all the latest PHPdoc and coding standards are passed.
Fixed Packagist for apiopenstudio_admin – sorry, this was my bad – it was a copy and paste error that went unnoticed.
Contributors and developers using the codebase
If you have a clone of the Gitlab repository, you will need to update your remote branch with the following command (assuming you have cloned with SSH):
If you have a clone of the GitLab repository, you will need to update your remote branch with the following command (assuming you have cloned with SSH):
Low-code solutions, as part of your IT landscape, are clearly gaining continuous traction. Low-code now, actually has its own Gartner Magic Quadrant!
Whilst a survey by the other big gun: Forrester, has said that in 2019, 37% of developers in Forrester’s worldwide survey were using or planning to use low-code products. By mid 2020, they predict that this number will rise to more than half of developers.
In 2019, 37% of developers in Forrester’s worldwide survey were using or planning to use low-code products. By mid-2020, we predict that this number will rise to more than half of developers, thanks in part to a renewed push by Microsoft for its PowerApps, Flow, Power BI, and Power Platform products. Microsoft’s “free” and good-enough products will be adopted both in straightforward and sophisticated use cases and serve as catalysts for further growth — and consolidation — in the low-code market.
Finally, to complete the trifecta, CapGemini have now included low-code in their “Top Ten Trends. So all three planets are aligned.
Forrester research found that 100% of enterprises who have implemented a Low-Code development platformhave received ROI (Forrester 2019, Large Enterprises Succeeding With Low-Code, viewed 23 June 2021, https://assets.appian.com/uploads/2019/03/forrester-tlp-lowcode.pdf).
But… As ever, a lot of what we read out there is a mix of genuine analysis and the marketing objectives of the company writing it. The question really becomes. Are your low-code strategy and applications hitting your “low-code Sweet Spot”?
What low-code solutions do you need & where? How big should you start with low-code? Who do they enhance? Also, importantly, where shouldn’t you use them?
It’s worth remembering that companies can go too far, trying to remove developer costs. Using low-code the wrong way or too widely can severely limit straight Jacket development options.
Developers and low-code
There is an ideal mix of 4 Key areas. That varies with each business & its development needs:
High level expensive developer talent.
Less experienced and lower cost developers.
The right people with skills to access low-code & no-code solutions.
What the industry is now calling “Citizen Developers” (keeping in mind they often know your business processes & requirements better than anyone).
Do you have the right low-code app in place? So your expensive front-end developers don’t have to hand the requirements of an API to an equally expensive back-end developer (who is juggling this with another task that is equally mission critical), even though the front-end Dev has little on that week & will move to lower value tasks.
Or to take advantage of the extra efficiency in the fact that they both no longer have to dedicate time to the communication of what the front-end developer wants?
Communications tasks are typically underestimated costs
With a low-code solution like ApiOpenStudio, front-end developers can go straight to API creation. This can be great if you need to even out the load in a team where they might otherwise be cooling their jets on less important tasks, where they have to spend time defining the API and then send it on to back-end developers to implement.
This flexibility and being able to quantify it is the key to tuning your low-code mix, as the team will become more efficient.
Finally if they are both flat out, can a lesser developer or in the right environment a cross trained “Citizen Developer” with basic JSON or YAML skills be deployed? Ideally they should be close to the project and its requirements.
Low-code enables members of the team closer to the requirements & product or project development to build and manage an API themselves. Using, and in many cases, replacing the time they would have used to communicate this to others with actually developing the product.
Equality does not exist in low or no-code
Low-code and no-code platforms exist on a spectrum. On one extreme, you have platforms offering very basic functionalities – i.e. simple form and logic creation, combined with rudimentary document automation capabilities. On the other, you have platforms allowing citizen developers to build large, end to end workflow solutions, encompassing features like e-signature integrations, multi-step approvals, email reminders and data management.
So time and thought needs to put into the use-cases that you want to address with low-code implementations. This will prevent you facing the, often frustrating situations that project or product managers, when developers reply “nope, that can’t be done” due to the limitations of the software.
The balance
Like just about all movements in IT that become long-term, there is still a lot more to it in terms of taking it to your business and marketplace than the initial Marketing Hype. The real sustainable change is almost always different and requires a deeper understanding of how things really work to make sure the rubber hits the road.
So what do you really need to consider to realise the value of low-code across an organisation?
The fact is that low-code involves a trade-off, that is worth doing, but a trade-off nonetheless.
On the one hand, low-code enables those closest to the product and business requirements to build what they need and build it faster. It eliminates layers of process and management… business units can, in the right environment, move forward without consulting IT. Low-code makes business Agility happen, as it changes how the business works with software.
HOWEVER……
The fact is, though highly effective for many businesses, with low-code, the MORE you use it, the more you straighten your development. That is the trade off.
This is one of the reasons why pro-code (or pure developers) have little to fear from low-code. Though surveys show many of them fear this, it is not shown in the data. Particularly during the next decade, where Microsoft recently estimated that there would be a shortfall of one million developers in the USA alone.
Being able to plan and resource your company’s low-code mix, as well as advise where it is not appropriate (like when your CFO thinks he can do all with low-code just to save money!!) is becoming part of the career skill set for professional developers.
How low can you go?
Low-code, by definition also enables Fast Followers. As they have a pathway to follow that is quicker and lower revalue. So I would think twice about ever letting your marketing dept tell the world how you got there.
We think it’s important to realise (after years of researching & discussing this market trend with stakeholders) low-code and pro-code do not cancel each other out. No organisation should aim to be one or the other.
So the “Democratisation of development”, like all of the most successful democracies… need good checks and balances. judges, oversight and impartiality in the execution.
Summary
So as you would expect, there are quantifiable :aspects to this:
Is it giving you enough power, while liberating you from increasing development cost? Due to the rising price of developers and the need for an increasing number of developers, as companies race to meet the demand for providing richer digital experiences.
Whole platforms for this is not the place to start, & may not be the place to go. But starting with something like API creation and management can reduce both cost of running the internal Apps, the outward business and web apps that the customer sees. In most cases, these apps will rely heavily on external feeds and there is a high benefit in the low-code approach to this.